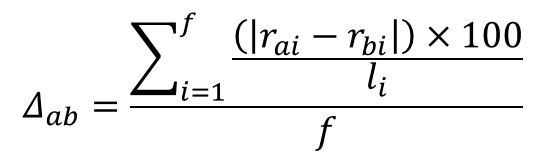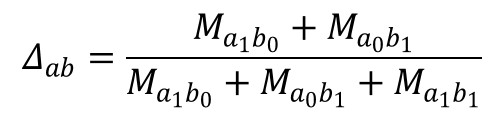FLARES is an online, open-source software for free-list analyses.
FLARES was developed to overcome some of the limitations of its direct ancestor FLAME which is a set of VBA macros running under Microsoft Excel (Pennec et al., 2012).
While maintaining the same philosophy - making free-list analysis as user-friendly as possible - FLARES offers:
- An extended accessibility. Web-based, you just need a web-browser and you can access FLARES from any operating system.
- Regular updates. Users are always sure to work with the latest version of FLARES as the application is regularly updated on the server.
- Integrated statistical analyses. While FLAME required the use of third-party software to conduct exploratory and multivariate analyses, the latter have been directly integrated into FLARES through the use of existing R packages (listed in the 'About' sub-tab).
- A user-friendly and interactive interface. The use of rStudio's shiny package allows for an interactive interface allowing user's to generate tables and aesthetic plots without ever modifying their original data.
Please visit the other sub-tabs of this 'Introduction' to learn more about FLARES and how to use it.
If you are familiar with R and rStudio you may run FLARES locally on your computer by forking the application on GitHub.
The development of FLARES has been made possible through the support of:


FLARES' development was finalized in 2017 while the main author was funded by a post-doctoral grant awarded by the FYSSEN Foundation.
The idea of developing FLARES sprang within the international research program PIAF (Interdisciplinary Program on indigenous indicators of Fauna and Flora) during which large datasets of free-lists were collected in four different countries (Cameroon, France, USA and Zimbabwe).
Free-listing is a data collection task which was elaborated in the field of cognitive psychology in order to better understand the processes of semantic categorization. Its use has become widespread in the fields of cognitive anthropology, ethnobiology and socio-ecological studies. It is an elicitation technique by which informants are asked to cite - in written or oral form - all the items belonging to a specific super-ordinate semantic category (or cultural domain). A typical question engaging such an elicitation would be:
Please cite, as they come to mind, all the insects that you know of.
This simple data collection technique may be used to:
- Explore the contents and structure of the investigated cultural domain by:
- Defining the semantic boundaries of the cultural domain.
- Uncovering the most culturally salient items of the domain (based on their frequency of mention across lists and their rank of citation within lists). See Smith & Borgatti (1997) and Sutrop (2001).
- Estimating inter-item semantic proximity based on the position of any pair of items within respondents' lists. See Henley (1969) & Winkler-Rhodes et al. (2010).
- Test for the existence of different patterns of response among groups of resondents by:
- Breaking down cultural salience results by categories of resondents (defined by user).
- Estimating respondents pairwise proximity based on the presence or absence of items within their lists.
Furthemore, the free-listing task may be accompanied by follow-up interviews in which respondents are prompted to provide categorical information concerning the items they have mentioned.
In such cases, statistical tests elaborated by Robbins and Nolan (1997, 2000) enable to test whether respondents:
- Present a bias in the order in which they mention items belonging to one category or the other (for dichotomous variables).
- Tend to cluster items in their list based on the category mentioned items belong to.
References:
- Medical Anthropology Wiki - Free Lists
- Field Methods Journal
- Bernard, H. Russell. 2018. Research Methods in Anthropology: Qualitative and Quantitative Approaches. Sixth edition. Lanham, MD: Altamira Press.
- Borgatti, Stephen P. 1999. 'Elicitation techniques for cultural domain analysis.' In J. Schensul & M. LeCompte (Eds.), Ethnographer's Toolkit, pp.1-26. Walnut Creek: Altamira Press.
- D'Andrade, Roy G. 1995. The development of cognitive anthropology. Cambridge; New York: Cambridge University Press.
- Weller, Susan C. & A. Kimball Romney. 1988. Systematic data collection. Newbury Park: Sage Publications.
Most instructions and references to the methods used by FLARES are built into the application and may be found in the different tabs of the application (sub-tabs with details are often named 'Methods').
Below, are provided the few necessary instructions to help you start using FLARES.
Before you can start using FLARES, you must submit an email address in the sidepanel of the 'Introduction' tab.
If you wish to do so, you may submit other information concerning yourself (Name and institution) or your dataset.
You may choose to allow other FLARES' users to access the information you have provided in the 'Users across the globe' sub-tab.
FLARES requires users to upload at least one file:
- In the 'Upload' tab: you must upload a .csv file containing free-lists, the name/id of respondents and, eventually, categorical information for mentioned items, if provided by respondents. Three different input formats are available and are illustrated in the 'Upload' tab.
To benefit from FLARES full capabilities you may also upload two other optional files:
- In the 'Normalization & Categorization' tab: you may upload a .csv file containing the unique list of all cited items, and as many supplementary columns in which original items may be corrected, translated (i.e. normalization columns) or categorized (i.e. categorization columns). The required input format is illustrated in the 'Normalization & Categorization' tab.
- In the 'Respondent Analyses' tab: you may upload a .csv file containing as many respondent variables as you wish. The required input format is illustrated in the 'Respondent Analyses' tab.
N.B. Files that you upload while using FLARES are not stored on the server's hardrive. Uploaded files are used temporarily as long as your session runs. As soon as your session ends, all of your data is cleared from the server's cache memory. However, we do recommend that any data that you upload should be anonymized in order to respect your respondents' privacy.
General guidelines and tips:
- You may generate your .csv files directly from Microsoft Excel or any other spreadsheet software.
- When possible, saving your .csv files into UTF-8 encoding is preferred.
- When possible, avoid special characters as well as periods, slashes or spaces (particularly in the column headings of your files).
- In the files you wish to upload do not leave header columns blank and do not give identical names to different columns.
All set to go!
FLARES - Free List Analysis under R Environment using Shiny
v 1.0
Fork us on GitHub and access the application's source code:GitHub Page
Citing FLARES
A paper on FLARES is to be published in a peer-reviewed journal shortly.
Meanwhile, you can cite FLARES as follows:
Wencelius, J., Garine, E., Raimond, C. 2017. FLARES. url:www.anthrocogs.com/shiny/flares/
FLARES is placed under a GNU Affero General Public License v3.0
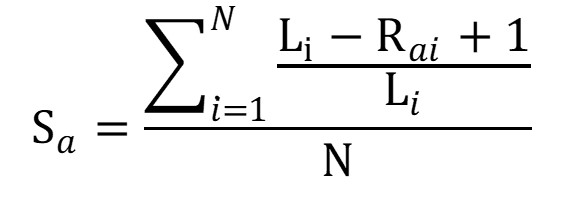
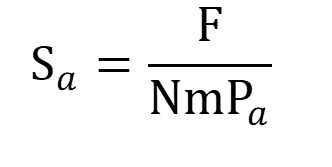
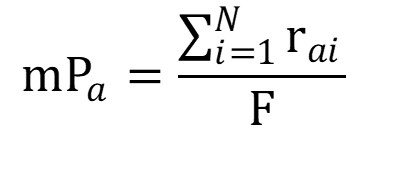 With:rai: rank of citation of item a in list i
With:rai: rank of citation of item a in list i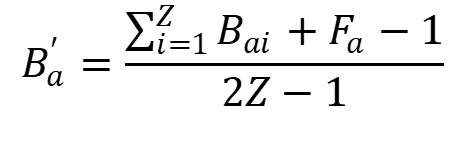
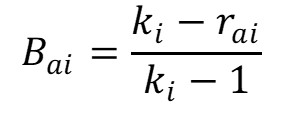 With:ki: length of list irai: rank of item a in list i
With:ki: length of list irai: rank of item a in list i